How to Design a Rate Limiter API | Learn System Design
How to Design a Rate Limiter API
A Rate Limiter API is a tool that developers can use to define rules that specify how many requests can be made in a given time period and what actions should be taken when these limits are exceeded.
Rate limiting is an essential technique used in software systems to control the rate of incoming requests. It helps to prevent the overloading of servers by limiting the number of requests that can be made in a given time frame.
It helps to prevent a high volume of requests from overwhelming a server or API. Here is a basic design for a rate limiter API In this article, we will discuss the design of a rate limiter API, including its requirements, high-level design, and algorithms used for rate limiting.
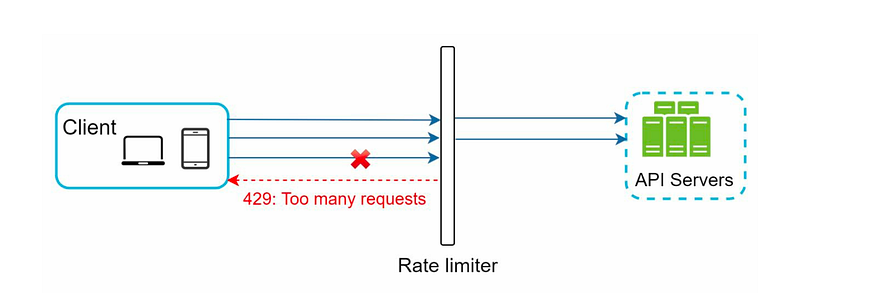
Why is rate limiting used?
- Avoid resource starvation due to a Denial of Service (DoS) attack.
- Ensure that servers are not overburdened. Using rate restriction per user
- ensures fair and reasonable use without harming other users.
- Control the flow of information, for example, prevent a single worker from
- accumulating a backlog of unprocessed items while other workers are idle.
High Level Design (HLD) to Design a Rate Limiter API
Where to place the Rate Limiter - Client Side or Server Side?
A rate limiter should generally be implemented on the server side rather than on the client side. This is because of the following points:
Key Components in the Rate Limiter
- Define the rate limiting policy: The first step is to determine the policy for rate limiting. This policy should include the maximum number of requests allowed per unit of time, the time window for measuring requests, and the actions to be taken when a limit is exceeded (e.g., return an error code or delay the request).
- Store request counts: The rate limiter API should keep track of the number of requests made by each client. One way to do this is to use a database, such as Redis or Cassandra, to store the request counts.
- Identify the client: The API must identify each client that makes a request. This can be done using a unique identifier such as an IP address or an API key.
- Handle incoming requests: When a client makes a request, the API should first check if the client has exceeded their request limit within the specified time window. If the limit has been reached, the API can take the action specified in the rate-limiting policy (e.g., return an error code). If the limit has not been reached, the API should update the request count for the client and allow the request to proceed.
- Set headers: When a request is allowed, the API should set appropriate headers in the response to indicate the remaining number of requests that the client can make within the time window, as well as the time at which the limit will be reset.
- Expose an endpoint: Finally, the rate limiter API should expose an endpoint for clients to check their current rate limit status. This endpoint can return the number of requests remaining within the time window, as well as the time at which the limit will be reset.
Where should we keep the counters?
We can rely on two commands being used with in-memory storage,
- INCR: This is used for increasing the stored counter by 1.
- EXPIRE: This is used for setting the timeout on the stored counter. This counter is automatically deleted from the storage when the timeout expires.
In this design, client requests pass through a rate limiter middleware, which checks against the configured rate limits. The rate limiter module stores and retrieves rate limit data from a backend storage system. If a client exceeds a rate limit, the rate limiter module returns an appropriate response to the client.
Algorithms to Design a Rate Limiter API
Several algorithms are used for rate limiting, including
- The Token bucket,
- Leaky bucket,
- Sliding window logs, and
- Sliding window counters.
Let's discuss each algorithm in detail-
Token Bucket
The token bucket algorithm is a simple algorithm that uses a fixed-size token bucket to limit the rate of incoming requests. The token bucket is filled with tokens at a fixed rate, and each request requires a token to be processed. If the bucket is empty, the request is rejected.
The token bucket algorithm can be implemented using the following steps:
- Initialize the token bucket with a fixed number of tokens.
- For each request, remove a token from the bucket.
- If there are no tokens left in the bucket, reject the request.
- Add tokens to the bucket at a fixed rate.


🪙 Token Bucket — like saving coins in a jar 💰
Imagine:
-
You have a jar (bucket) that can hold 10 coins (tokens).
-
Every second you get 1 new coin from the bank.
Rules:
-
To send 1 request, you must spend 1 coin.
-
If you have coins saved, you can spend them all quickly at once.
-
If no coins are left, you must wait for new coins to come.
Example:
-
You didn’t use the API for 10 seconds → jar is full (10 coins)
-
Now you suddenly send 10 requests at once → all 10 succeed
-
Now jar is empty → you must wait for coins to refill
✅ You can save up and then burst many requests at once.
This is called burst allowed.
💧 Leaky Bucket — like water leaking from a bottle 🚰

Imagine:
-
You have a bottle with a small hole at the bottom.
-
Water drops (requests) come into the bottle from the top.
-
The bottle lets out only 1 drop every second, no matter how many are inside.
-
If too many drops come at once → bottle overflows and some drops are thrown away.
Example:
-
You send 10 requests at the same time
-
Bottle accepts them, but lets them go out 1 per second
-
So your 10 requests will come out slowly over 10 seconds
-
If you send 100 at once → bottle overflows → extra are rejected
❌ You cannot burst fast.
✅ It forces steady speed always.
🪙 Token Bucket
-
Requests can come slowly or all at once (burst)
-
If tokens are saved, they can be processed all together quickly
-
⚡ So it allows burst traffic
📝 Example: 10 tokens saved → you can send 10 requests in 1 second
💧 Leaky Bucket
-
Requests can come fast, but they will be processed one by one slowly at a fixed rate
-
❌ So it does not allow burst processing
-
⚖️ It makes traffic smooth and steady
📝 Example: 10 requests come at once → they go out 1 request per second
For high-scale payment systems like UPI, the Token Bucket algorithm is typically the most suitable for rate limiting.
It works by giving each user a ‘bucket’ of tokens, where each token allows one request.
Tokens refill at a fixed rate over time.
This approach allows short bursts of transactions, which is important for legitimate use cases like paying multiple bills quickly, while still controlling the average request rate to prevent system overload.
Token Bucket is also efficient in distributed environments, as it can be implemented using Redis or other in-memory stores.
In addition, systems may combine it with Sliding Window Counters for real-time monitoring and detecting suspicious activity, but Token Bucket forms the core mechanism because it balances throughput, fairness, and burst handling effectively.”
🪙 Token Bucket for Daily Transactions
1️⃣ First Transaction of the Day
-
User makes their first UPI transaction today
-
System checks: Does this user have a bucket?
-
❌ No → create a new bucket for this user
-
✅ Yes → use existing bucket
-
-
The bucket stores:
-
currentTokens→ how many requests they can make right now -
lastRefillTime→ when tokens were last refilled
-
2️⃣ Subsequent Transactions
-
User makes more transactions
-
For each request:
-
Refill tokens based on time passed since last refill
-
Check if
currentTokens >= 1 -
✅ Allow request → subtract 1 token
-
❌ Block request → not enough tokens
4️⃣ Daily Behavior
-
If user doesn’t transact for days, bucket may expire (TTL) → deleted from Redis
-
On the next transaction, a new bucket is created automatically
-
System does not store a token per transaction. Tokens are just counters, not individual objects.
Now suppose the user makes 10 transactions today:
| Step | What happens in bucket |
|---|---|
| User makes 1st txn | 1 token consumed → 9 left |
| User makes 2nd txn | 1 token consumed → 8 left |
| … | … |
| User makes 10th txn | 1 token consumed → 0 left |
| Wait some time | Tokens start refilling over time |
⚡ Tokens are only “available capacity” to make requests right now
⚙️ In Sliding Window Log
“For every user, in the last X seconds (window size), allow at most Y requests.”
This window size (X) is the only time you configure.
📌 Definition
Sliding Window Log is a rate limiting algorithm that
stores the timestamp of each request and
allows only a fixed number of requests within a moving time window.
⚙️ Step 1 — Store current time
-
When a request comes, get current time from system clock
-
Example: at 2s, 4s, 6s (just examples)
-
-
Put this time in a list (log)
→log = [2,4,6]
⚙️ Step 2 — Remove old entries
-
Also get the current time again
-
Remove any time that is older than (currentTime - 10)
Example:
-
Now current time = 12 sec
-
Remove any time
< 12 - 10 = 2 -
From
log = [2,4,6]→ 2 is not older, so keep it
If time = 15 sec:
-
remove any
< 15 - 10 = 5 -
from
[2,4,6]→ remove 2,4 → now[6]
This is how the list always only stores last 10 seconds’ requests
So you don’t need to know start/end time
— you just delete old ones on each request
📌 Summary
-
On each request:
-
now = current time -
remove all timestamps
< now - windowSize -
if list size < limit → allow, else block
📌 Definition
Sliding Window Counter is a rate limiting algorithm that
divides time into fixed windows (like 10-sec blocks) and
counts how many requests came inside each block.
Then, to smooth it, it also looks at the previous window’s count (partial).
Sliding Counter = Count how many in this block of time.
(Fast but not very accurate).
What it does:
-
Breaks time into fixed blocks (like 1-minute windows)
-
Keeps a count of how many requests in each block
-
When a new request comes:
-
Check how many are in current + previous window (with weight)
-
If count > limit → block
📊 Example
-
Rule: 10 requests per 1 minute
-
Time windows: 0–60s, 60–120s
| Time | Window | Count |
|---|---|---|
| 50s | 0–60 | 10 |
| 61s | 60–120 | 10 |
⚠️ These 20 requests are just 11 seconds apart →
Allowed due to window boundary → called boundary burst problem
Detailed Design of a Rate Limiter:
Here we are using the below components:
- Config and data store to store the rate limiter rules
- Workers frequently pull rules from the disk and store them in the cache
- Rate Limiter Middleware fetches rules from the cache. It also fetches data such as timestamps, counter etc. from Redis. Then it does the computation when a request comes and decides whether to process the request or rate limit it.
- In case of rate limiting the request — here we have 2 options
- Option 1: To drop the request and send a status code of 429: too many requests back to the client.
- Option 2: Push it to a Message queue to process this request later.

Race condition
Read the counter value from Redis and check if ( counter + 1 ) exceeds the threshold. If not, increment the counter value by 1 in Redis.

Assume the counter value in Redis is 3 (as shown in the image above). If two requests concurrently read the counter value before either of them writes the value back, each will increment the counter by one and write it back without checking the other thread. Both requests (threads) believe they have the correct counter value 4. However, the correct counter value should be 5.
Locks can be useful here, but that might impact the performance. So we can use Redis Lua Scripts.
- This may result in better performance.
- Also, all steps within a script are executed in an atomic way. No other Redis command can run while a script is executing.
Synchronization in Distributed Rate Limiting – Easy Version
1️⃣ Why do we need synchronization?
-
Imagine millions of users are sending requests.
-
One server cannot handle all traffic alone → so multiple rate limiter servers are used.
-
Problem: If each server tracks requests independently, a user could bypass limits by hitting different servers.
-
✅ Solution: synchronize the rate limiter data across servers.
Synchronization ensures:
-
Only one server updates the token bucket at a time (atomic operations)
-
Prevents race conditions across servers
-
Guarantees consistent rate limiting.
2️⃣ Sticky sessions? Not ideal
-
One idea: send the same user always to the same server (sticky session)
-
❌ Problem:
-
Not scalable
-
Not flexible → if server fails, the user is blocked
3️⃣ Better approach: Centralized store
-
Use a centralized store like Redis
-
All rate limiter servers read/write tokens or counters from the same place
-
Ensures consistency: no matter which server handles the request, the limit is enforced correctly
4️⃣ Monitoring & adjusting
-
After setup, we should monitor metrics:
-
Performance → Are requests fast?
-
Rules → Are too many valid requests being blocked?
-
Algorithm effectiveness → Can it handle bursts or flash traffic?
-
-
Examples:
-
If rules are too strict → relax limits
-
If sudden traffic spikes occur (flash sale) → switch to an algorithm like Token Bucket to allow short bursts


✅ Key Points
-
RateLimiterImplseparates API from algorithm. -
Strategydecides how to rate-limit (token, window). -
Storedoes atomic state changes in Redis. -
RateLimitConfigdefines limits. -
RateLimitResultgives full info to caller.
Explanation of Numbered Steps
-
Client initiates a request to check rate limiting.
-
RateLimiterImpl is the main entry point; calls Strategy.
-
RateStrategy handles the algorithm (token bucket).
-
Store fetches the current bucket state (tokens + last refill time).
-
Bucket calculates refill tokens based on elapsed time and checks if enough tokens exist.
-
Bucket updates state after consuming tokens.
-
Store writes updated state back atomically (Lua script or transaction).
-
Store acknowledges update → ensures distributed consistency.
-
Strategy returns final result (allowed/denied + metadata).
-
RateLimiterImpl returns response to client.
-
Client gets final boolean or structured result.
Components
| Component | Role |
|---|---|
| RateLimiter (interface) | Public API → allowRequest(userId) |
| RateLimiterImpl | Implementation → delegates logic to Strategy |
| Strategy (TokenBucket/FixedWindow) | Algorithm to enforce limits (token refill, window calc) |
| Store | Persistent state (Redis or DB) |
| RateLimitConfig | Holds config: windowSize, maxTokens, refillRate, burst |
| RateLimitResult | Return object: allowed, remaining, retryAfterMs |
Scenario-based questions (real-world interview prompts)
Question:
“You have an API that allows 100 requests per user per minute. A user suddenly sends 200 requests in 1 minute. How would you handle this?”
Answer:
-
Use a rate limiting algorithm (Token Bucket or Sliding Window Counter).
Question:
“Multiple users are hitting your service, and you have multiple rate limiter servers. How do you ensure consistent enforcement?”
Answer:
-
Problem: Without synchronization, a user can bypass limits by hitting different servers
-
Solution:
-
Centralized store (Redis) for tokens or counters
-
Atomic updates (increment/decrement tokens)
-
Optional distributed lock if multiple servers may update same bucket simultaneously
-
-
Avoid sticky sessions: they limit scalability and create single point of failure
Design a highly-available distributed rate limiter for an API gateway supporting 100M users. (System-design style)
Scaling to 100M Users
-
Sharding: Partition users across multiple Redis shards using consistent hashing.
-
Replication: Each shard replicated (master-slave) for HA.
-
Eviction Policy: Use TTL for counters to reduce memory (only store active users).
-
Cache only hot users: Cold users can fetch counters from DB or on-demand.
High Availability
-
Multi-region Redis clusters for geo-redundancy.
-
API Gateway deployed in multiple regions with DNS-based load balancing.
-
Circuit breaker / fallback mechanism: if rate limiter fails, allow requests with safe defaults.
Monitoring & Metrics
-
Track requests per second, rate-limit hits.
-
Use Prometheus + Grafana.
-
Alerts when Redis or limiter nodes are overloaded.
Lua script for atomic check + increment
KEYS[1] = "rate_limit:userId"
ARGV[1] = max_tokens
ARGV[2] = refill_rate
-- refill logic
local current = redis.call("GET", KEYS[1])
if not current then current = ARGV[1] end
-- check if enough tokens
if current > 0 then
redis.call("DECR", KEYS[1])
return 1 -- allowed
else
return 0 -- rate limited
end
Each request hits this Lua script for atomic operation.
-
Guarantees no race conditions.
✅ Summary Design
-
API Gateway nodes distributed globally.
-
Each node uses token bucket algorithm.
-
Counters stored in sharded Redis cluster with TTL.
-
Atomic increments via Lua scripts.
-
Monitoring, metrics, multi-region failover.
-
Scalable to 100M users.
2. Flow of a Transaction / API Request
-
Client request → hits Load Balancer.
-
Load Balancer → forwards request to one of the API Gateway nodes.
-
API Gateway Node:
-
Calls Rate Limiter module.
-
Rate Limiter checks token bucket for the user:
-
Key:
userId:apiId -
Stored in Redis cluster.
-
-
-
Redis Cluster:
-
Provides atomic check & decrement using Lua script.
-
Returns:
-
Allowed → Gateway forwards request to backend service.
-
Rejected (429) → Gateway returns rate-limit exceeded to client.
-
-
-
Rate Limiter Updates:
-
TTL ensures counters auto-expire after window.
-
Token bucket refills at fixed rate.
-
-
Backend Service:
-
Processes request if allowed.
-
Notes on High Availability & Scalability
-
Load Balancer distributes traffic to API Gateway nodes.
-
API Gateway nodes are stateless → can scale horizontally.
-
Rate Limiter relies on Redis cluster:
-
Sharded by userId to scale horizontally.
-
Replicated for failover.
-
Lua scripts ensure atomic increments and prevent race conditions.
-
-
TTL-based eviction keeps memory low (store only active users).
A. Use a single source of truth for time
-
Use Redis server time instead of local node time for rate limiter operations.
B. Synchronize clocks across nodes
-
Use NTP (Network Time Protocol) to keep system clocks in sync.
C. Avoid relying on local node time
-
For distributed token buckets or sliding windows, store last refill timestamp in Redis rather than trusting local machine time.
Atomicity: Lua ensures all steps are atomic → no race condition even in distributed API gateways.
-
Sharding: For massive users, store keys in a Redis Cluster, shard by
userId. -
TTL: Use
EXPIREto free memory for inactive users. -
Time source: Use Redis server time (
TIMEcommand) instead of local node time to avoid clock skew. -
Burst support: Capacity allows short bursts above steady rate.
-
Scaling: Multiple API nodes can call the same Redis cluster safely.
Deep technical / follow-ups (what interviewers will probe)
-
How to implement the refill efficiently at high scale without periodic jobs? (Answer: compute tokens lazily using last_timestamp and rate when a request arrives; no background refills.)
-
Explain time and memory complexity for sliding log vs counters. (Sliding log: O(r) per key where r is requests in window; sliding counter: O(1) approximate.)
-
How to enforce fairness when multiple clients share a quota? (Weighted token buckets or fair queueing; implement per-client weights and scheduler.)
-
How to test rate limiter? (Unit tests for algorithm, integration with Redis (use test-containers or mock Redis), load tests with Gatling/JMeter; test boundary times and concurrency.)
-
Monitoring & alerting metrics to expose: allowed rate, blocked rate, token refill rate, top N keys, latency of limiter, Redis latency, dropped requests.
Comments
Post a Comment